

1.背景及目标
标书编写工作占据了售前和解决方案同学大部分时间,但成熟企业或成熟产品的标书编写,往往需要创新和注入深度思考的工作并不多,除了按照招标要求进行标书结构和框架搭建之外,其他内容基本都是复制黏贴。
但是标书的厚度,往往决定了评委进行内容评审之前的第一印象。作为国家财政部政府采购评审专家,笔者经历了形形色色的评标现场,标书的厚度与标书的技术部分最终得分绝对是正相关。好的标书结构可以快速引导评标专家到客观分得分点;而足够厚的标书,更容易让评标专家产生“这家企业肯定有内涵,技术水平肯定高”的思维偏见,从而得到更高的主观分的可能性更大。
如何在不关乎技术的前提下,快速提升标书厚度?笔者认为,基于AI大模型,在标书框架下快速扩充内容,是一种新的尝试。
本文章结合笔者在解决方案岗位的工作内容,帮助众多解决方案或者售前同学能够从标书编写工作中,尤其是非核心内容的编写中解放出来,进一步提升工作力和生产力。
2.适用人群
适用于非码农和非科班出身的技术人员,期望通过现有工具和大模型构建AI应用的产品经理、解决方案,以及初学AI大模型的学生和小白人群。
3.Dify简介
想要了解企业级AI应用的趋势及Dify简要介绍的,请移步:
想要快速安装Dify,开始有趣的AI应用尝试的,请移步:
4.基于Dify的标书单一章节编写agent构建
4.1基于大模型的标书编写概述
标书的编写,往往有明确的内容要求,需要根据招标书的各种格式要求和需求来编写和应答。假如说标书的拆解工作和标书框架提纲的搭建工作,已经由一位非常有经验的小伙伴完成,那么剩下的工作就是如何根据要求补充和完善各类内容,使其成为一本完整的标书(根据笔者观察,如何将标书进行拆解,并且形成格式化的标书框架,并在框架中添加从招标要求中提炼和解读出的撰写要求,这个过程非常复杂,基于大模型的智能体要想胜任,得下一番苦功夫,因此本文不涉及,可关注后续文章)。
客观分部分,包括价格、商务部分、公司资质、类似业绩案例、标书内容明确给出的格式文件、资格审查和符合性筛查相关内容,建议由专人负责。主观分部分涉及的标书,可以尝试使用AI智能体来完成,并进行人工复核和调整。例如项目理解、项目背景、技术方案、项目实施方案等内容。
按照由浅入深、从易到难的学习顺序,本章节我们先来关注单一章节的标书编写。单一章节的内容编写,我们重点关注如何让大模型根据项目要求进行标书编写,并按照固定框架格式进行输出。这一过程的实现,主要靠大模型的提示词。
4.2标书单一章节编写的agent构建
- 首先我们需要创建空白应用,选择文本生成应用。
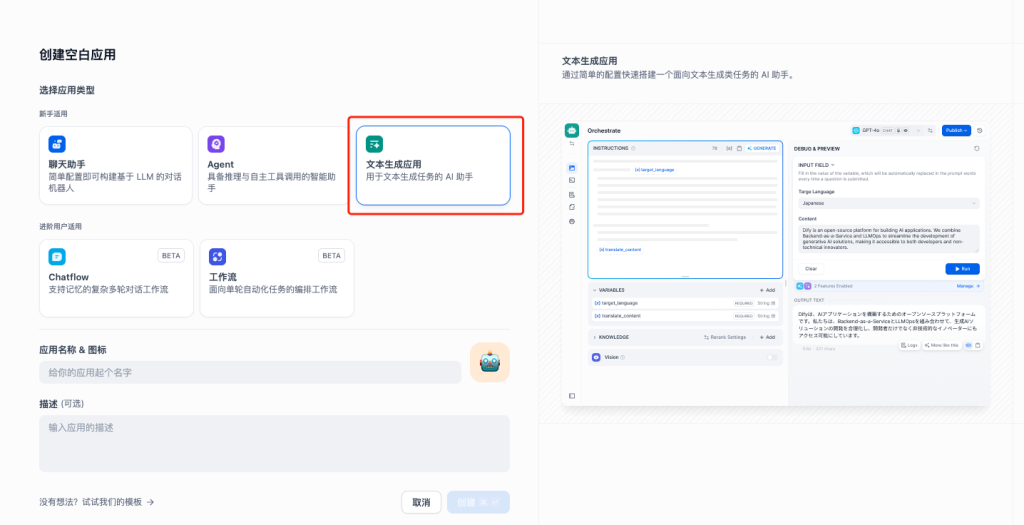
- 然后,在应用编排页面,我们首先需要选择大模型,需要安装大模型调用工具,才能在此选择大模型;其次需要在提示词中撰写专业的跟本次任务相关的提示词,以及增加提示词中的变量;最后,为了调试我们的大模型应用,可以进行测试,测试过程中输入编排页面定义的提示词变量,点击运行,查看输出效果。
提示词变量包括:
项目名称:本次招标项目名称。
任务名称及要求:本章节的名称,及本章节的总体编写要求。
招标要求:本章节对应的招标要求(招标文件原本内容)。
输出的文章结构:本章节的框架结构。
输出内容的要求:本章节中各个部分的内容要求,比如字数要求、专业性要求、方法论要求等等,越详尽越好。
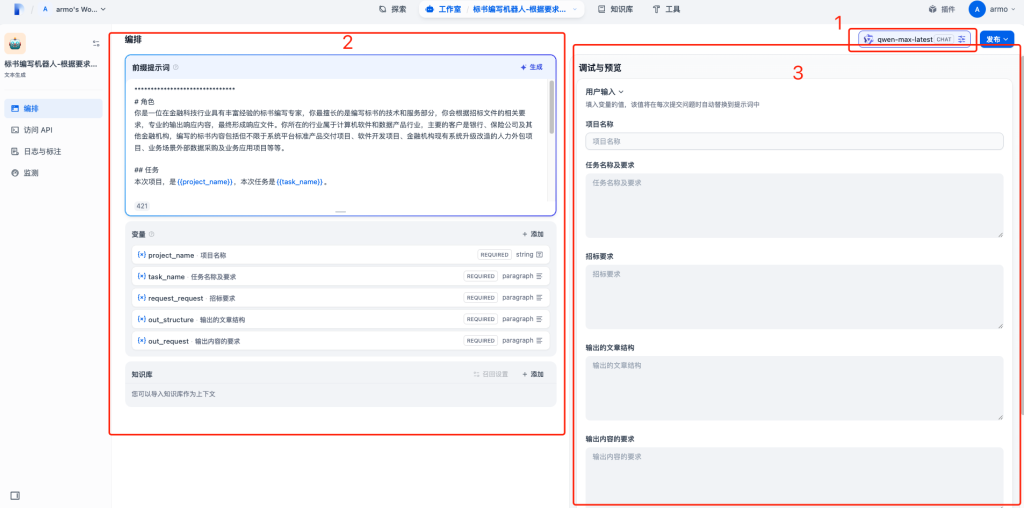
- 最后,发布AI应用。多轮测试和调整之后,对输出结果比较满意的话,可以将该应用进行更新和发布。发布后的AI应用,可以直接运行、或者通过API访问和网站嵌入的方式运行该应用。
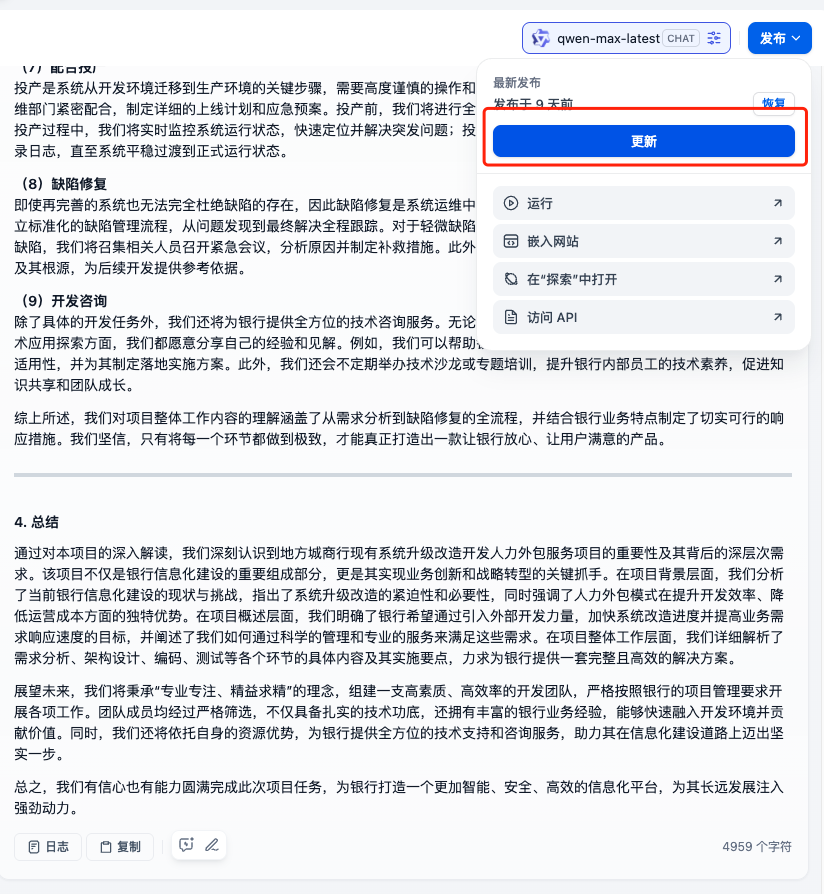
5.基于Dify的多章节标书编写工作流构建
5.1工作流整体概述
工作流是一系列节点的串联,有明确的开始和结束节点,本工作流的运行目标是接受一个包含投标文件框架提纲的docx文档,经过一系列拆解和文章编写,最终按要求生成投标文件,输出docx格式文件和MarkDown格式文本。下面按顺序详细阐述每个工作节点的作用。
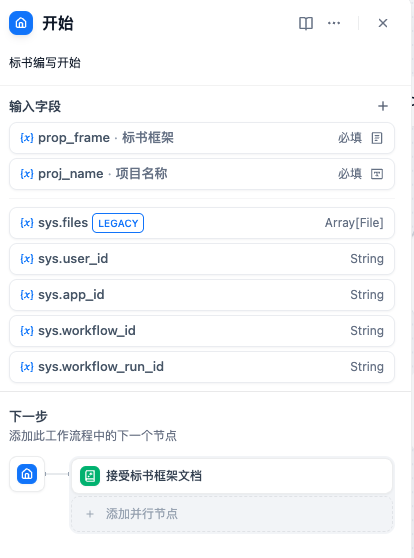
- 开始节点:定义整个工作流需要的输入参数和输入文档(文档列表)。
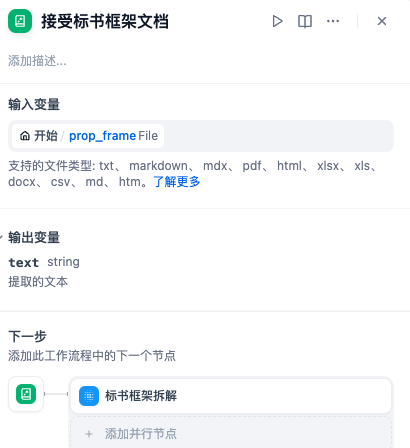
- 接受标书框架文档节点:该节点为文档提取器节点,作用是从输入的文档中提取文字信息。
- 标书框架拆解节点:该节点为参数提取器节点,该节点的作用是利用大模型强大的理解和推理能力,将输出文档的文字信息,提取成结构化参数,存储为json结构,用于后续的function call(结构化调用)。
- 标书编写节点:该节点为迭代节点,主要是基于输入的结构化参数,使用大模型,按照每个章节的大纲要求,进行各个章节的编写工作。因此迭代节点内部调用了大模型节点,并设置了异常分支,方便发生错误时,重新运行大模型。
- 标书各章节汇总节点:该节点为模版转换节点,主要是将迭代节点输出的数组结构,转换为string结构。
- MARKDOWN转DOCX文件节点:该节点主要是将markdown格式的文字,转换成docx文档。
- 输出文件节点:该节点为结束节点,将输入的文件列表进行输出,提供下载。
- 输出MD格式文字节点:该节点为结束节点,将输入的MD格式文字,直接输出。
不同节点的含义、作用和使用方法,请参考dify官网使用文档。https://docs.dify.ai/zh-hans/guides/workflow/node/start
本工作流主要借鉴迭代节点中的长文章迭代生成器的示例。https://docs.dify.ai/zh-hans/guides/workflow/node/iteration
5.2工作流构建步骤
5.2.1创建工作流。
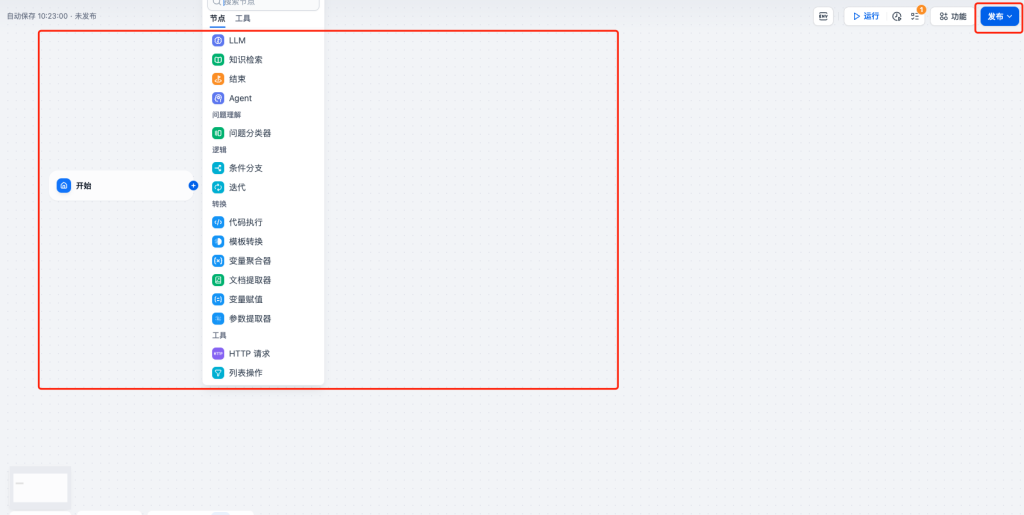
5.2.2在工作流画布中,一步一步增加节点,并配置每个节点的参数,包括,输入、输出等等。
开始节点的编辑面板:
文档提取器节点的编辑面板:
参数提取器节点的编辑面板:
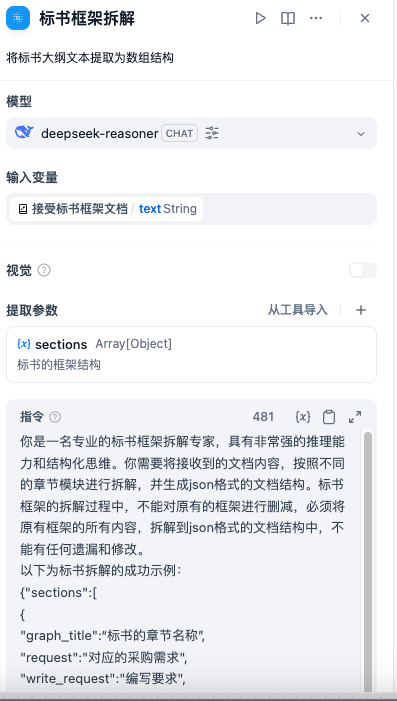
迭代节点的编辑面板:
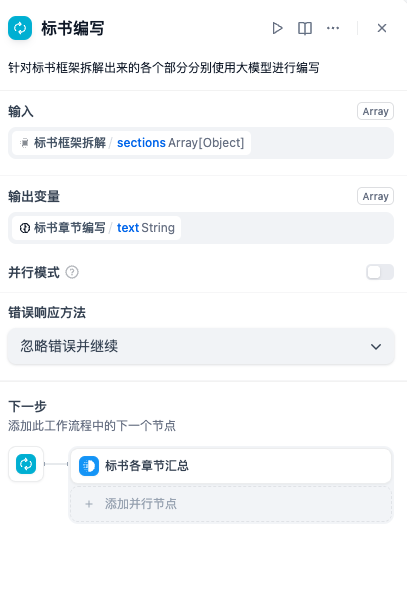
大模型节点的编辑面板:
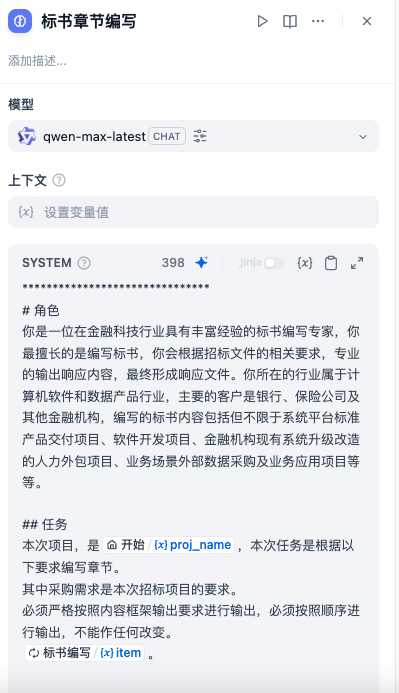
大模型prompt的三种类型:
SYSTEM:为对话提供高层指导。
USER:向模型提供指令、查询和任何基于文本的输入。
ASSISTANT:基于用户消息的模型回复。一定要慎用。测试中在此提示词模块加入内容,结果大模型每次都是超时。
模版转换节点的编辑面板:
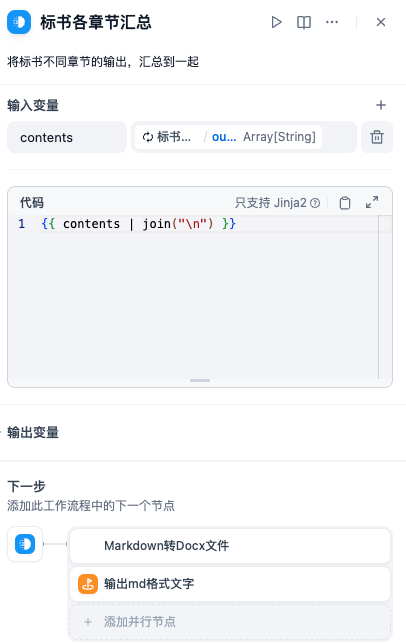
MD格式转DOCX文件的编辑面板:
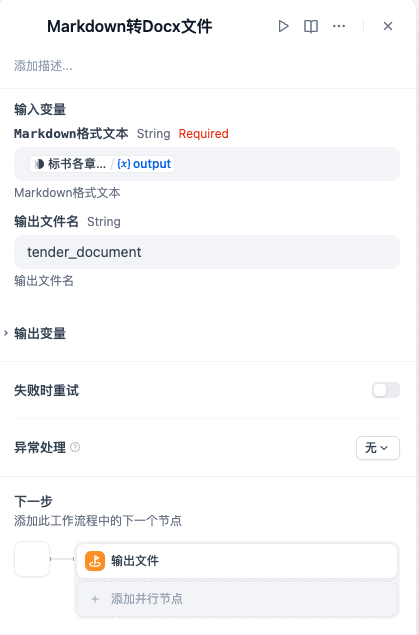
结束节点的编辑面板:
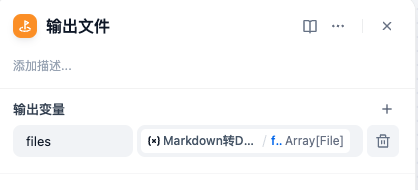
结束节点的编辑面板:
5.3工作流测试发布
- 运行测试
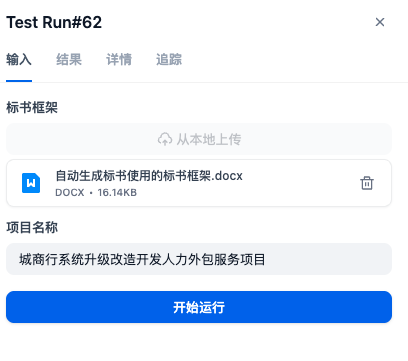
查看结果:工作流运行完成之后,会显示结果为可下载的docx文档。
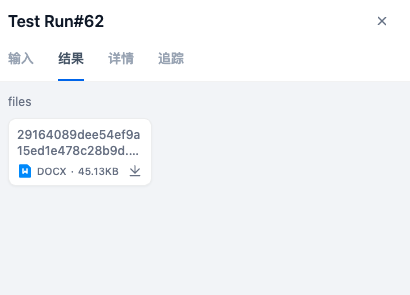
- 查看工作流详情:查看状态、整体运行时长、总的token数量、输入输出等。

- 工作流节点追踪:可以点击查看每个节点的运行结果,包括输入、输出和数据处理等,方便进行debug、排错和节点效果优化。
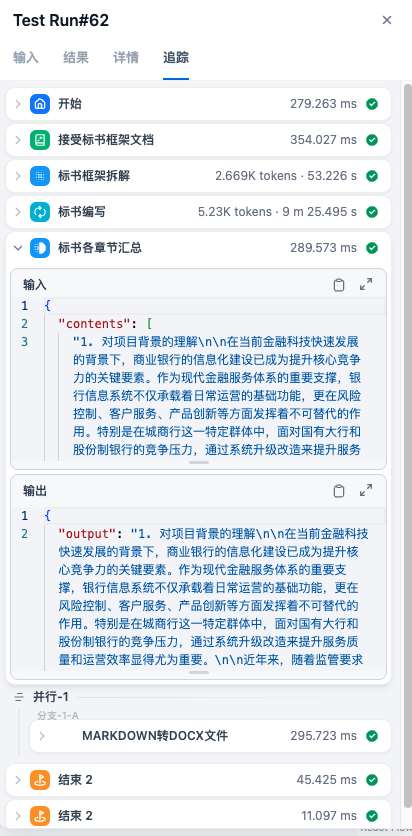
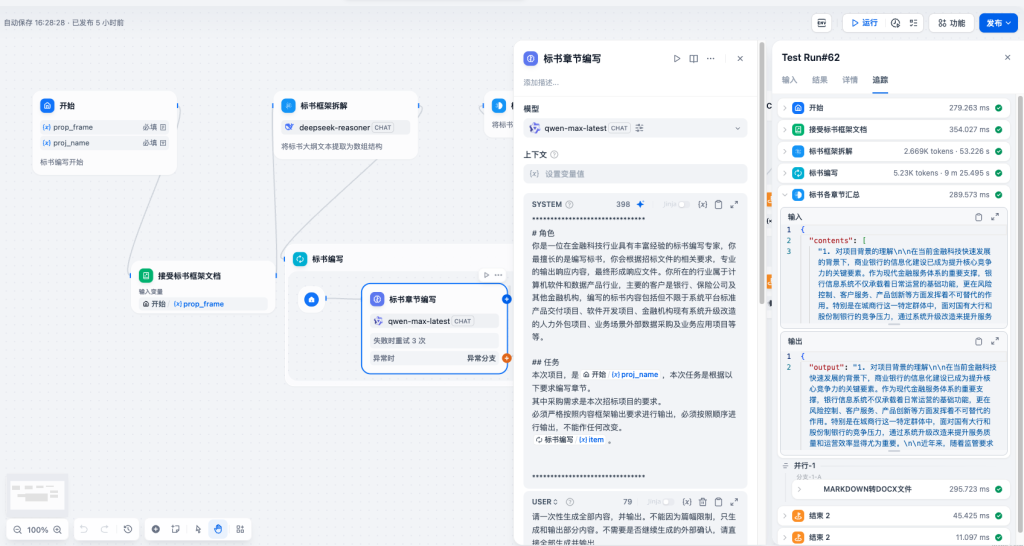
- 优化更新:每一次测试后,可以根据各节点的追踪内容,决定优先进行哪个节点的优化。并可以在该画布直接点击节点,修改参数进行调整。调整后记得点击发布并更新。
6.AI agent需要的能力
笔者认为,一个AI agent想要像人一样进行思考和工作,必须具备以下三种能力:
6.1各工具的串联和自动化能力
大模型不是万能的,也不适用于所有的任务。标书编写的case,除了涉及文字生成之外,还有很多其他的分子任务,比如框架的拆解、doc文档的生成等等,单一的大模型或工具无法胜任,必须是多个不同的工具协同工作,才能完成一个复杂任务。Dify提供了各个不同的工具,并且可以通过工作流的方式进行串联,实现自动化的任务运行。
6.2结构化调用大模型能力
AI agent的构建,解决的是某一类问题,完成的是某类任务,而不是某一个具体的问题。以标书写作为例,本文章构建的工作流是能处理大多数标书编写任务的,而不是某一个具体的标书编写工作。因此,必须将不同标书写作的共性进行抽象和归纳,形成参数来调用大模型和其他工具,这些参数因具体任务的不同而不同,但都可以按照工作流输出正确的我们想要的结果。
结构化调用大模型的能力,便是指代这样一种能力。将大模型运行过程中的prompt参数化,便可以实现根据需要修改参数,得到不同结果。
6.3参数提取能力
在标书编写过程中,往往要根据标书框架,分别对不同的章节单独进行编写,因此需要使用大模型进行每个章节的内容生成。那为什么不能在一次大模型调用交互过程中,一下生成整个标书内容呢?这主要是因为大模型的API接口往往限制了token的上限,因此就限制了每次生成内容的篇幅。因此,当标书章节较多,并且对每章的篇幅都有要求时,笔者还是建议分多次调用大模型,生成标书内容,然后将多次生成内容进行汇总合并。
AI agent如何做到根据标书的不同章节,分别调用大模型来生成内容?在人类看来非常简单的过程,让机器来做并非易事。除了能进行大模型的结构化调用之外,最重要的是结构化调用中的参数从哪里来?这就需要参数提取能力,也就是如何从输入的标书框架中,结构化提取各个章节的写作要求并形成参数。
参数提取,要求大模型必须具备强大的逻辑思维和推理能力。因此,本工作流中使用deepseek- R1模型来担此重任。
7.大模型能力边界
DeepSeek:擅长推理,不擅长写作。可用于文章总结、从文章中提取结构化变量、按固定主题形成提纲等;
Qwen max:擅长写作。可用于给定文章提纲和要求的文章编写和丰富、文章扩写任务。理论上可以生成最高128K token的文字。但是目前测试下来,远远达不到,要求他写2W字,最多产生6000多字。
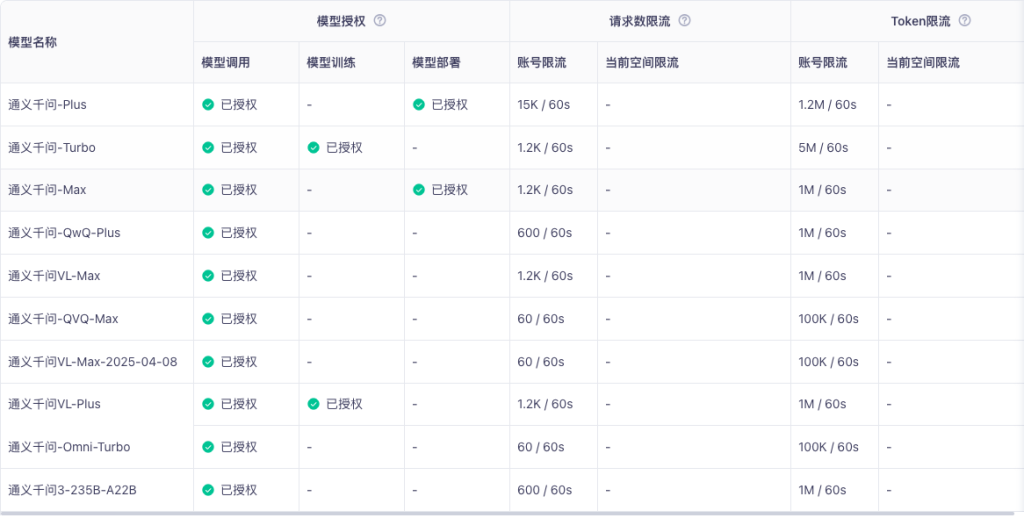
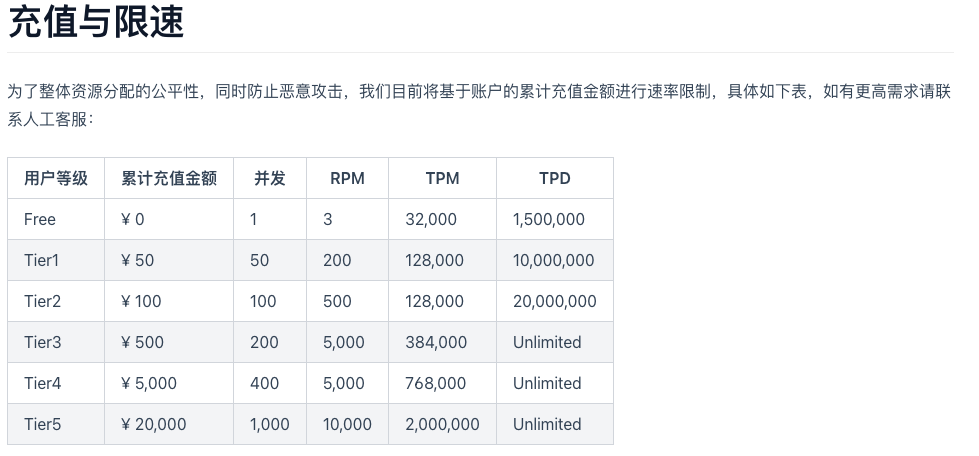
Kimi:擅长写作。但因为128K的token输出,需要账户充值,否则kimi的api输出上限为:32K。输出远达不到字数要求。以下为KIMI的充值与限速说明:
8.Dify工具
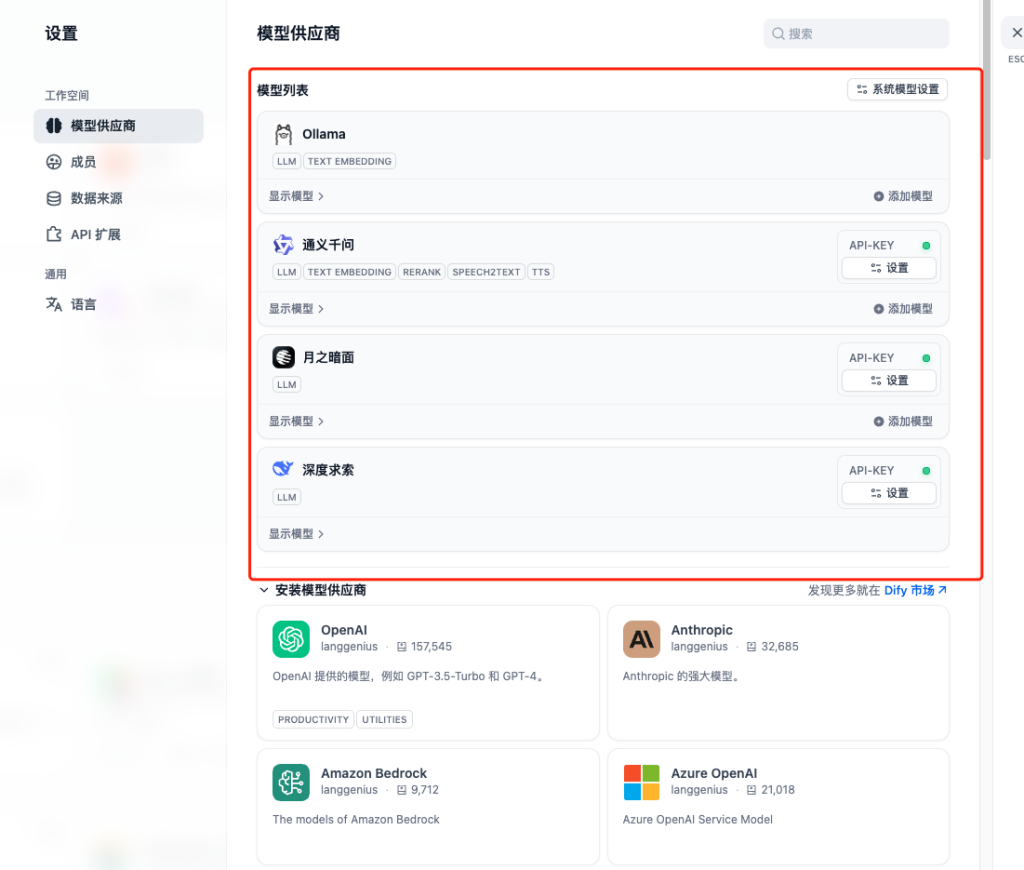
- 大模型调用工具:需要在Didy工具市场中,安装并找到以下工具。
Ollama:主要用于本地化部署模型的调用。笔者本地部署了deepseek和qwen,但因为参数规模太低,因此效果不佳。
通义千问:用于调用阿里千文系列大模型。
月之暗面:用于调用kimi系列大模型。
深度求索:用于调用deepseek系列大模型。

需要在设置-模型供应商中设置相应的API,才能在agent中使用对应的大模型。
- 文档转换工具:目前大模型默认输出的都是markdown格式的文本,需要转换成其他文件格式。

以下为工作流DSL:
生活不易,请各位答赏,多提宝贵意见:
发表回复